(Italiano) Quando i dati diventano “big”…. Hadoop!
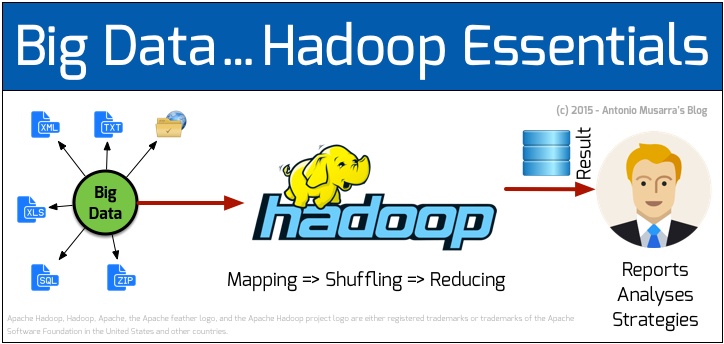
Chi non ha sentito parlare di Big Data negli ultimi tempi? Sempre più le dimensioni dei dataset gestiti da alcune organizzazioni e aziende (gli apripista sono stati giganti come Google e Facebook) sono diventate così grandi e complesse (parliamo di PetaBytes, se non di ExaBytes) da richiedere strumenti differenti da quelli tradizionali in tutte le fasi del processo: dall’acquisizione, alla condivisione, all’analisi, fino alla visualizzazione dell’informazione. In molte situazioni, la gestione del dato attraverso piattaforme RDBMS basate su SQL non basta più: si parla infatti di soluzioni alternative di tipo noSQL. Tra queste, Hadoop è sicuramente la piattaforma oggi più diffusa per lavorare con i Big Data, in grado, perciò, di gestire:
- enormi volumi di dati in input;
- dataset eterogenei, laddove i dati sono poco e variamente strutturati;
- esigenza di risposte Near-Real-Time;
- necessità di calcolo parallelo
Tra l’altro, Hadoop è un progetto open source Apache. Per dirla tutta, Hadoop costituisce il “core” di un ecosistema fatto di progetti, quindi di strumenti, altrettanto open, che possono collaborare tra di loro per affrontare al meglio la sfida dell’incombente “diluvio di dati”.
In estrema sintesi, Hadoop è formato da due componenti fondamentali:
- HDFS, il file system
- MapReduce, il “motore”
HDFS rende semplice memorizzare e gestire file molto grandi:
- ottimizza la velocità di trasferimento sulla latenza, che è quello che vogliamo quando:
- scriviamo files con decine/centinaia di milioni di record (web pages);
- scriviamo ogni volta “una volta sola”, visto che il prossimo “crawl” riscriverà il file da zero.
MapReduce rende semplice operare con dati distribuiti:
- dopo aver suddiviso (split) il file in input su più blocchi (su più nodi), MapReduce è capace di operare sul file in parallelo facendo lavorare un processo di lettura indipendente su ogni blocco.
Forse conviene dare una chance ad Hadoop se il grep su qualche file di log sta impiegando 10 minuti o se la generazione del report SQL sta impiegando più di mezz’ora..
In questo articolo vedremo come, in pochi semplici passi, sia possibile installare Hadoop ed eseguire la nostra prima applicazione.
Installeremo Hadoop su Linux Ubuntu 12.04 LTS, ovviamente in configurazione single node.
Prerequisiti:
- Oracle Java JDK;
- Aggiunta di un utente di sistema dedicato Hadoop;
- Configurazione SSH;
Per installare Java 7, digitiamo i seguenti comandi:
|
1 2 3 |
sudo add-apt-repository ppa:webupd8team/java sudo apt-get update sudo apt-get install oracle-jdk7-installer |
Per verificare che l’installazione sia andata a buon fine digitiamo java -version che visualizzerà la versione di Java installata. Digitiamo quindi i seguenti comandi:
|
1 2 |
sudo addgroup hadoop sudo adduser --ingroup hadoop hduser |
che permetteranno di aggiungere l’utente hduser al gruppo hadoop sulla macchina locale.
Hadoop richiede un accesso tramite SSH per la gestione dei suoi nodi. Nel nostro caso permetteremo all’utente hduser di accedere al localhost configurando SSH eseguendo i seguenti comandi:
|
1 2 3 4 |
su - hduser ssh-keygen -t rsa -P "" Generating public/private rsa key pair. Enter file in which to save the key (/home/hduser/.ssh/id_rsa): |
a questo punto premendo invio comparirà i seguente output:
|
1 2 |
Created directory '/home/hduser/.ssh'. Your identification has been saved in /home/hduser/.ssh/id_rsa. |
e un’altra serie di messaggi che descrivono il risultato dell’esecuzione. Successivamente, forniamo un accesso SSH per accedere alla macchina con la chiave appena creata:
|
1 |
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys |
Per testare che la configurazione sia andata a buon fine digitiamo ssh localhost
A questo punto siamo pronti per scaricare l’ultima versione stabile di Hadoop, ad esempio da qui, e installarla in una directory a piacere, ad esempio in: /usr/local/hadoop:
|
1 2 3 4 |
cd /usr/local sudo tar xzf hadoop-2.4.0.tar.gz sudo mv hadoop-2.4.0 hadoop sudo chown -R hduser:hadoop hadoop |
Aggiungiamo le seguenti righe in fondo al file $HOME/.bashrc per l’utente hduser:
|
1 2 3 4 5 6 |
# Set Hadoop-related environment variables export HADOOP_HOME=/usr/local/hadoop # Set JAVA_HOME (we will also configure JAVA_HOME directly for Hadoop later on) export JAVA_HOME=/usr/lib/jvm/java-7-oracle # Add Hadoop bin/ directory to PATH export PATH=$PATH:$HADOOP_HOME/bin |
Infine, editiamo il file /usr/local/hadoop/etc/hadoop/hadoop-env.sh individuando la riga:
|
1 |
export JAVA_HOME=${JAVA_HOME} |
e sostituendola con la riga:
|
1 |
export JAVA_HOME=/usr/lib/jvm/java-7-oracle |
La configurazione di Hadoop, consiste nell’editare il file /usr/local/hadoop/etc/hadoop/core-site.xml.
In questo file possiamo ad esempio indicare la directory in cui Hadoop memorizza i data files, la porta di ascolto, etc. Editare il file, significa inserire i parametri di configurazione tra i tag xml configuration. Supponiamo di voler configurare il percorso di base per le directory in cui risiederanno i file di input e di output utilizzati dai job di MapReduce.
Innanzitutto creiamo una directory tmp:
|
1 2 3 |
sudo mkdir -p /app/hadoop/tmp sudo chown hduser:hadoop /app/hadoop/tmp sudo chmod 750 /app/hadoop/tmp |
Successivamente inseriamo le seguenti proprietà nel file core-site.xml:

Figura 1 – Configurazione del core di Hadoop
Allo stesso modo, possiamo gli altri due file principali di Hadoop. Editiamo mapred-site.xml con le seguenti proprietà:

Figura 2 – Configurazione del map reduce task
e hdfs-site.xml con le seguenti proprietà:

Figura 3 – Configurazione dei site per HDFS
Ultimata la configurazione, procediamo con lo start della nostra installazione. Prima di tutto, formattiamo il file system lanciando il comando:
/usr/local/hadoop/bin/hdfs namenode -format
Quindi, siamo finalmente pronti ad eseguire Hadoop, per farlo lanciamo: /usr/local/hadoop/sbin/start-all.sh
l’output del comando riporta la seguente linea significativa:
|
1 |
localhost: starting nodemanager, logging to /opt/hadoop-2.5.2/logs/yarn-hadoop-nodemanager-my_ubuntu.local.out |
dove my_ubuntu è il nome della macchina Linux.
Possiamo accedere all’interfaccia web di amministrazione Hadoop digitando il seguente indirizzo nel browser: http://localhost:50070.
Passiamo ora, come promesso, a una semplice applicazione di esempio.
Word Count sarà il nostro Hello World. Si tratta di un’applicazione che conta l’occorrenza di ciascuna parola in uno o più files di testo.
E’ uno di quei casi in cui l’applicazione in sè è decisamente banale, mentre l’implementazione lo è solo se la quantità di testo da analizzare è ragionevolmente piccola, in particolare se la RAM è sufficiente a contenerla.
Che significa, infatti, realizzare una versione di Word Count che funzioni su 500 GB o 1 TB di testo?
Hadoop elabora il dataset di input attraverso le due funzioni “primitive” map e reduce, la cui strategia di azione si può schematizzare nello schema seguente:

Figura 4 – Lo schema di azione dei task map e reduce
Il framework Hadoop, in maniera trasparente rispetto all’utente, organizza l’insieme di coppie chiave/valore emesse dai vari «map task» in modo che tutte quelle che hanno la stessa chiave siano inviate allo stesso «reduce task». A questo punto, la funzione «reduce» non deve far altro che sommare tutti i valori corrispondenti a quella chiave per produrre il risultato finale.
Bene, proviamo a fare il word count del contenuto di un libro. L’applicazione wordcount fa parte della libreria di esempi forniti di serie dal framework. Come dataset da “contare”, possiamo ad esempio liberamente scaricare i libri:
- Alice nel Paese delle Meraviglie:
http://www.gutenberg.org/ebooks/11.txt.utf-8 (testo semplice UTF-8: 164 Kb)
- La Divina Commedia:
http://www.gutenberg.org/ebooks/1012 (testo semplice UTF-8: 604 Kb)
Portiamo i files nella nostra macchina Linux (in /home/hadoop) lanciando:
|
1 |
[hduser@my_ubuntu bin]$ ./hadoop fs -put /home/hadoop/AliceInWonderland.txt /user/hadoop/input/ AliceInWonderland.txt |

Figura 5 – Browsing del file system HDFS
Quindi, eseguiamo l’applicazione lanciando il seguente comando:
|
1 |
[hduser@my_ubuntu bin]$ ./hadoop jar /opt/hadoop-2.5.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.2.jar wordcount /user/hadoop/input/ AliceInWonderland.txt /user/hadoop/output2 |
Viene creata la dir. /home/hadoop/output al cui interno troviamo il file part-r-00000 che rappresenta il risultato del wordcount. L’output sarà reperibile anche attraverso il comando:
|
1 |
[hduser@my_ubuntu ~]$ ./hadoop fs -get /home/hadoop/output{,} |
e il seguente non è che un piccolo estratto:

Figura 6 – Estratto dell’output dopo l’esecuzione dell’esempio precedente
Semplice, no? Bene, se invece di poche centinaia di KB vorrete esaminare qualche TB, non avete che da accomodarvi…
Se poi vorrete mettere alla prova il “vero” Hadoop, predisponendo il calcolo parallelo su qualche decina o centinaia di nodi, allora significherà che questo articolo avrà conquistato davvero il vostro interesse!















