Running Kettle Job by Java API

In questo breve articolo vedremo come sia possibile e semplice utilizzare le API di Pentaho Data Integration (Kettle) [1] per eseguire dei Job in precedenza progettati con il designer Spoon[2]. Non sarà oggetto di trattazione dell’articolo la parte di design che riguarda sia le Trasformazioni sia i Job.
L’articolo è rivolto a chi già possiede buone conoscenze di base dell’architettura e del funzionamento di Kettle. La versione di riferimento delle API è la 4.1 Community Edition.
1. Scenario
Consideriamo un ipotetico caso per cui abbiamo la necessità d’integrare all’interno della nostra applicazione Java l’esecuzione di un Job (di ETL[3]) creato precedentemente con lo strumento Spoon. La possibilità di poter eseguire questo scenario c’è data dalle API di Kettle.
In Figura 1 e Figura 2 sono mostrati Job e Trasformazione che sono i pezzi del puzzle che in parte costituiscono il nostro scenario d’integrazione. Il processo di ETL ha l’obiettivo di leggere un insieme di dati anagrafici di persone fisiche, su questo insieme applicare una serie di trasformazioni e poi creare un file di output (in formato XML) integrato con l’informazione del codice fiscale. L’informazione aggiuntiva del codice fiscale proviene da un servizio web di pubblico dominio.
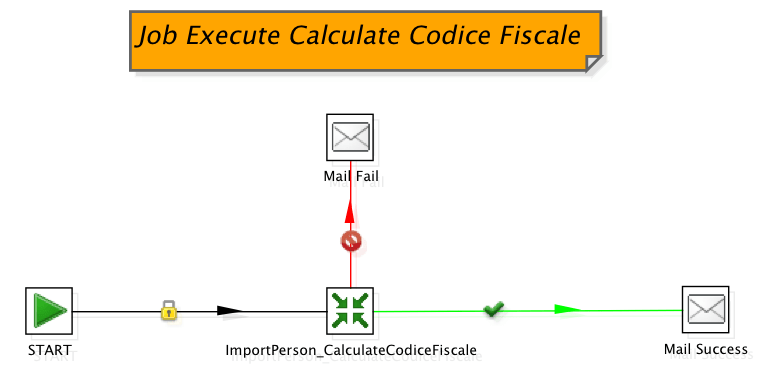
Figura 1 Job che esegue la trasformazione per l’integrazione del codice fiscale.
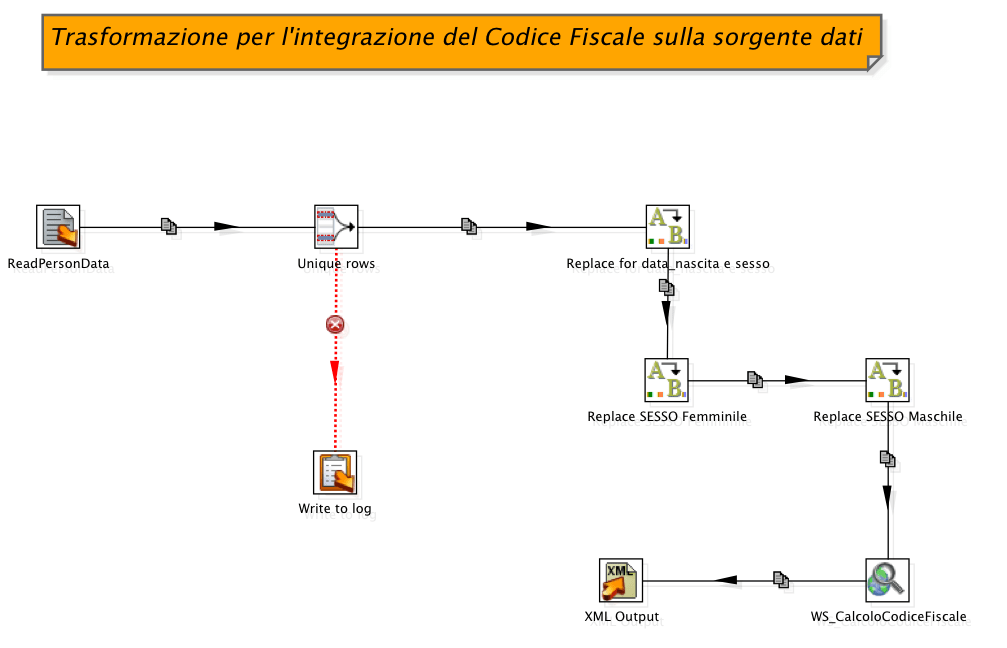
Figura 2 Trasformazione che integra i dati letti in input con il codice fiscale.
Il Job ExecuteCalculateCodiceFiscale illustrato in Figura 1, nello scenario ipotizzato deve essere eseguito dalla nostra applicazione Java. Il Job esegue la Trasformazione indicata in Figura 2, in caso di successo o fallimento esegue l’invio di una notifica via email. I requisiti necessari per portar a termine l’integrazione con la nostra applicazione Java sono:
- Kettle API 4.1
- Configurazione dell’ambiente Kettle
- Accesso al repository di Kettle
L’ambiente di data integration supporta tre tipologie diverse di repository che sono:
- Kettle Database Repository
- Kettle File Repository
- Pentaho Enterprise Repository (disponibile solamente con l’edizione Enterprise di Pentaho)
Il metodo di accesso al repository è garantito attraverso un’unica interfaccia indipendentemente dal tipo di repository. Per i repository basati su db e su file i “driver” di accesso sono disponibili sul core, al contrario, il “driver” di accesso all’Enterprise Repository è disponibile come plugin.
E’ fondamentale che l’ambiente di Kettle sia correttamente configurato, in particolare l’environment KETTLE_HOME, su questa directory il motore di Kettle esegue la ricerca e il caricamento dei plugin disponibili.

Figura 3 Overview scenario d’integrazione.
2. Overview sulle Kettle API
Oltre a fornire strumenti di data integration e business intelligence,Kettle, ha un set di API che possono essere utilizzate per scopi d’integrazione. Le API di Kettle sono divise in quattro principali categorie:
- Core: package che contiene tutte le classi core di Kettle, memorizzate nel file kettle-core.jar.
- Database: package che contiene le classi riguardanti i data base supportati da Kettle. Le classi sono memorizzate nel file kettle-db.jar.
- Engine: package che contiene le classi di runtime di Kettle memorizzate nel file kettle-engine.jar.
- GUI: package che contiene tutte le classi riguardanti l’interfaccia utente (come Spoon) memorizzate nel file kettle-ui-swt.jar.
L’implementazione e la successiva esecuzione dello scenario illustrato in precedenza, richiedono l’utilizzo di un certo set di API o meglio di package, quali:
- org.pentaho.di.core: package che contiene tutte le classi necessarie all’inizializzazione dell’ambiente operativo di Kettle.
- org.pentaho.di.job: package che contiene tutte le classi necessarie alla manipolazione (creazione, modifica, esecuzione, etc…) dei Job.
- org.pentaho.di.repository: package che contiene tutte le classi necessarie per l’accesso al repository dei metadati.
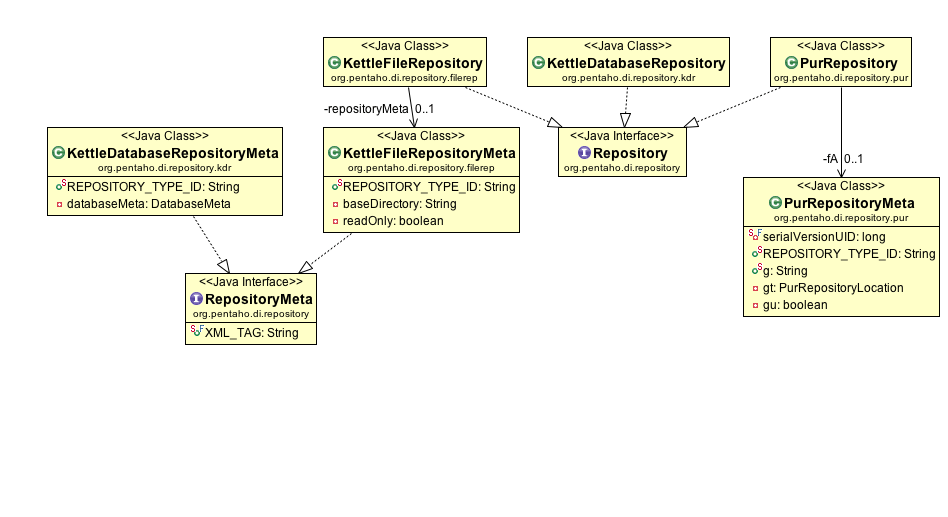
In Figura 4 è mostrato il class diagram delle classi base utilizzate ai fini dell’integrazione, mentre in Figura 4.1 è illustrato il class diagram che mostra le relazioni tra le principali classi che hanno a che vedere con il concetto di repository.
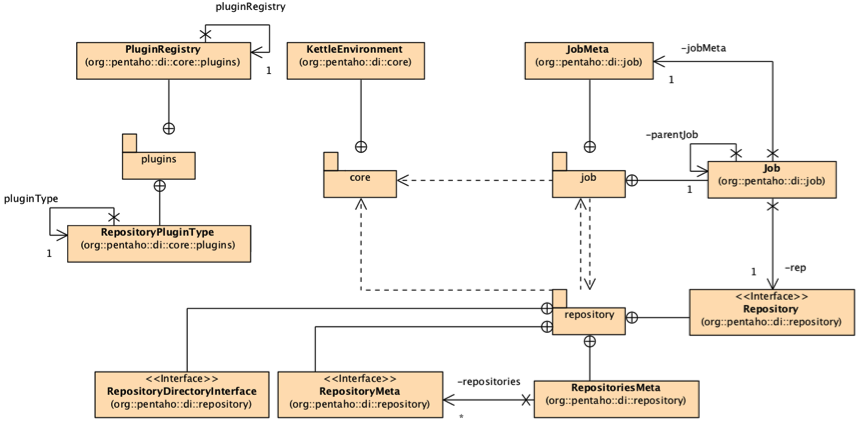
Figura 4 Class Diagram delle classi base di Kettle.
3. Scheletro della classe Java
Dopo aver dato un rapido sguardo alle API di Kettle (quelle di nostro interesse), in questo paragrafo vedremo come costruire uno scheletro di base per una classe Java che sia in grado di eseguire un generico Job. Credo che la cosa migliore per fissare in mente ciò che si vuole ottenere, sia rappresentare tutte le attività necessarie al raggiungimento dell’obiettivo attraverso il diagramma di attività illustrato in Figura 5.
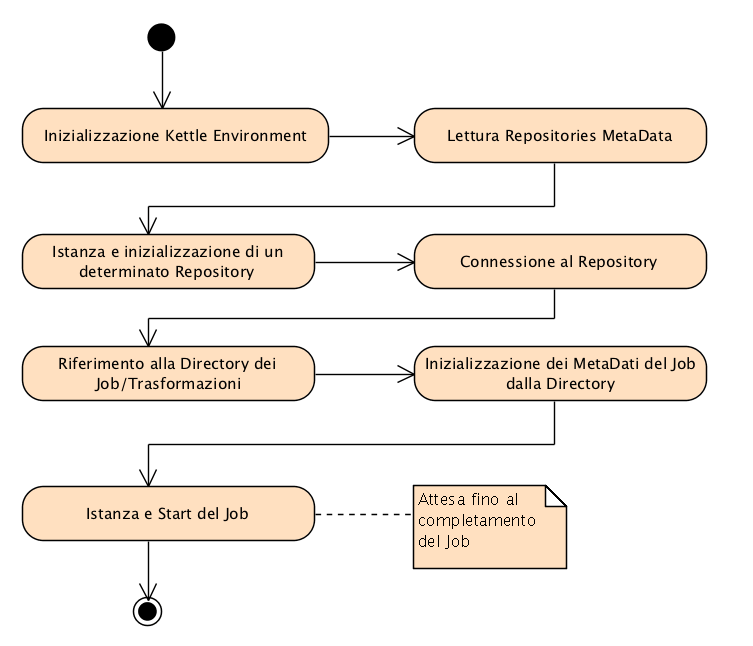
Figura 5 Activity Diagram per l’esecuzione di un Job.
Tutte le attività indicate nel diagramma sono abbastanza chiare da non richiedere successivi approfondimenti, come d’altronde anche lo stesso flusso. L’esecuzione di ogni singola attività si traduce nell’utilizzo di una o più classi del set di API Kettle indicate nel precedente paragrafo.
Andando alla parte puramente pratica, al Listato 1 è mostrata la semplice classe ExecuteGenericJob della nostra ipotetica applicazione Java che è in grado di eseguire uno dei Job definiti nel repository a cui è possibile accedere. Ricordo che il Job di nostro interesse si chiama ExcuteCalculateCodiceFiscale.
Nel Listato 1, per ragioni di spazio ho preferito mostrare il solo corpo della classe, indicando le parti di codice core, quelle che rispecchiano le attività indicate nel diagramma di Figura 5.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
KettleEnvironment.init(); RepositoriesMeta repositoriesMeta = new RepositoriesMeta(); repositoriesMeta.readData(); RepositoryMeta repositoryMeta = repositoriesMeta.findRepository("1"); PluginRegistry registry = PluginRegistry.getInstance(); Repository repository = registry.loadClass(RepositoryPluginType.class, repositoryMeta, Repository.class); log.logBasic("Repository Description: " + repositoryMeta.getDescription()); repository.init(repositoryMeta); repository.connect("admin", "admin"); RepositoryDirectoryInterface directory = repository .loadRepositoryDirectoryTree(); directory = directory.findDirectory("ShirusKettleDirectory"); JobMeta jobMeta = new JobMeta(); jobMeta = repository.loadJob(filename, directory, null, null); log.logBasic("JobMeta Description: " + jobMeta.getDescription()); log.logBasic("JobMeta Version: " + jobMeta.getJobversion()); log.logBasic("JobMeta Modify Date: " + jobMeta.getModifiedDate()); log.logBasic("JobMeta Id: " + jobMeta.getObjectId().getId()); Job job = new Job(repository, jobMeta); log.logBasic("Job Name: " + job.getJobname()); job.start(); job.waitUntilFinished(); if (job.getErrors() != 0) { log.logError("Job Error: " + job.getErrors()); log.logError("Error encountered!"); } |
Listato 1 Corpo della classe Java ExecuteGenericJob (on Gist.GitHub ).
Il codice della classe java illustrato nel Listato 1 rispecchia quanto descritto nel diagramma di attività di Figura 5, ogni blocco di codice evidenziato (indicato con un box numerato) implementa esattamente nell’ordine, quanto descritto dalla relativa attività.
Le informazioni riguardanti il repository cui connettersi, sono disponibili nel file di configurazione repositories.xml. Ricordo che le API di Kettle fanno riferimento alla variabile d’ambiente KETTLE_HOME come base di ricerca per tutti i file di configurazione, occorre quindi assicurarsi che questa variabile d’ambiente sia correttamente impostata.
Il tipo di repository utilizzato è basato su data base MySQL. Sono supportati i più comuni tipi di data base per il repository.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
<repositories> <connection> <name>Kettle Repository on shirus-pentaho-suite-00</name> <server>shirus-pentaho-suite-00.lab.roma.dontesta.it</server> <type>MYSQL</type> <access>Native</access> <database>kettle_4_1_repository</database> <port>3306</port> <username>kettle</username> <password>Encrypted 2be98afc86aa7f2e4cb79a575ca86a3df</password> <servername/> </connection> <repository> <id>KettleDatabaseRepository</id> <name>1</name> <description>kettle-amusarra-repository</description> <connection>Kettle Repository on shirus-pentaho-suite-00</connection> </repository> </repositories> |
Listato 2 Estratto dal file di configurazione del Repository Kettle (repositories.xml on GistGitHub).
E’ consentito definire uno o più repository, ecco il motivo per cui una delle attività svolte dalla classe java è per l’appunto la creazione dell’istanza di un determinato repository (vedi blocco 3 del Listato 1). Il repository è organizzato per directory, ogni directory contiene quindi oggetti come Job e Trasformazioni, il nostro Job da eseguire risiede all’interno della directory ShirusKettleDirectory (vedi blocco 5 del Listato 1). Il resto del codice della classe java parla da solo da non richiedere altri approfondimenti.
4. Esecuzione del Job
Ipotizziamo di voler eseguire il nostro Job direttamente dalla console, confezioniamo quindi una classica applicazione java il cui corpo del metodo main contiene l’intero codice java discusso nel precedente paragrafo. Nel Listato 3 è mostrata l’implementazione completa della classe java che è in grado di eseguire uno dei Job definiti nel repository di Kettle. Per ragioni di spazio sono stati omessi alcuni dei blocchi di codice visti nel precedente paragrafo.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 |
package it.dontesta.lab.jobs.kettle; importorg.pentaho.di.core.KettleEnvironment; importorg.pentaho.di.core.logging.LogChannel; import org.pentaho.di.core.logging.LogChannelInterface; import org.pentaho.di.core.plugins.PluginRegistry; import org.pentaho.di.core.plugins.RepositoryPluginType; import org.pentaho.di.job.Job; import org.pentaho.di.job.JobMeta; import org.pentaho.di.repository.RepositoriesMeta; import org.pentaho.di.repository.Repository; import org.pentaho.di.repository.RepositoryDirectoryInterface; import org.pentaho.di.repository.RepositoryMeta; public class ExecuteGenericJob { public static void main(String[] args) throws Exception { String jobName = args[0]; KettleEnvironment.init(); … JobMeta jobMeta = new JobMeta(); jobMeta = repository.loadJob(jobName, directory, null, null); Job job = new Job(repository, jobMeta); job.start(); job.waitUntilFinished(); if (job.getErrors() != 0) { log.logError("Job Error: " + job.getErrors()); log.logError("Error encountered!"); } } } |
Listato 3 Classe Java per l’esecuzione di un Job Kettle.
Il programma java ExecuteGenericJob richiede un parametro d’input che corrisponde al nome del Job da eseguire.
$ java it.dontesta.lab.jobs.kettle.ExecuteGenericJob ExecuteCalculateCodiceFiscale
Listato 4 Esecuzione del Job ExecuteCalculateCodiceFiscale.
Il comando mostrato nel Listato 4 esegue il programma java passando come argomento il nome del Job. Nei due successivi listati (Listato 5 e Listato 6) sono mostrati gli output generati dal programma java, sia in caso di successo, sia in caso di fallimento, quest’ultimo a causa di un errore di connessione al repository.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
INFO 06-02 20:25:53,130 - Using "/var/folders/Ze/ZeZnC-m0GParEA44C74AVk+++TI/-Tmp-/vfs_cache" as temporary files store.INFO 06-02 20:25:54,036 - RepositoriesMeta - Reading repositories XML file: /Users/amusarra/.kettle/repositories.xml INFO 06-02 20:25:54,111 - ExecuteGenericJob - Repository Description: kettle-amusarra-repositoryINFO 06-02 20:26:14,612 - ExecuteGenericJob - JobMeta Description: Job che esegue la trasformazione per l'integrazione del Codice FiscaleINFO 06-02 20:26:14,612 - ExecuteGenericJob - JobMeta Version: 1.0 INFO 06-02 20:26:14,612 - ExecuteGenericJob - JobMeta Modify Date: 2011-01-31 15:51:54.0 INFO 06-02 20:26:14,612 - ExecuteGenericJob - JobMeta Id: 2 INFO 06-02 20:26:14,617 - ExecuteGenericJob - Job Name: ExecuteCalculateCodiceFiscale INFO 06-02 20:26:14,618 - ExecuteCalculateCodiceFiscale - Inizio dell'esecuzione del job INFO 06-02 20:26:14,622 - ExecuteCalculateCodiceFiscale - Inizio entry [ImportPerson_CalculateCodiceFiscale] INFO 06-02 20:26:14,624 - ImportPerson_CalculateCodiceFiscale - Caricamento della trasformazione dal repository [ImportPerson_CalculateCodiceFiscale] nella cartella [/ShirusKettleDirectory]INFO 06-02 20:26:16,051 - ExecuteCalculateCodiceFiscale - Inizio entry [Mail Success] INFO 06-02 20:26:16,166 - Mail Success - Added file '///Users/amusarra/Progetti/PentahoKettleAPI/KettleAPI-4.1.1/ImportPerson_CalculateCodiceFiscale.log' to the mail message. INFO 06-02 20:26:16,401 - ExecuteCalculateCodiceFiscale - Terminata jobentry [Mail Success] (risultato=[true]) INFO 06-02 20:26:16,402 - ExecuteCalculateCodiceFiscale - Terminata jobentry [ImportPerson_CalculateCodiceFiscale] (risultato=[true]) INFO 06-02 20:26:16,402 - ExecuteCalculateCodiceFiscale - L'esecuzione del job è terminata |
Listato 5 Output generato dal programma java ExecuteGenericJob in caso di successo (on GistGitHub).
|
1 2 3 4 5 6 |
INFO 06-02 19:05:02,864 - Using "/var/folders/Ze/ZeZnC-m0GParEA44C74AVk+++TI/-Tmp-/vfs_cache" as temporary files store.INFO 06-02 19:05:04,034 - RepositoriesMeta - Reading repositories XML file: /Users/amusarra/.kettle/repositories.xmlINFO 06-02 19:05:04,141 - ExecuteGenericJob - Repository Description: kettle-amusarra-repositoryException in thread "main" org.pentaho.di.core.exception.KettleException:Error connecting to the repository! Error occured while trying to connect to the database |
Listato 6 Output generato dal programma java ExecuteGenericJob in caso di errore (on GistGitHub).
Il codice d’esempio potrebbe non funzionare correttamente nel caso di repository di tipo Enterprise (il cui accesso è garantito tramite plugin). L’errore è solitamente dovuto a un problema di configurazione della KETTLE_HOME, ovvero, in fase d’inizializzazione dell’ambiente Kettle, tramite il metodo KettleEnvironment.init() avviene la lettura dei plugin e successivo caricamento (vedi Figura 6 e Figura 7).

Figura 6 Eccezione per plugin non disponibile

Figura 7 Errore durante la lettura della configurazione dei repository
4.1 Nota su KettleEnvironment.init()
La classe KettleEnvironment contiene le impostazioni e le proprietà per tutto il Kettle. L’inizializzazione dell’ambiente avviene chiamando il metodo init() che legge nei file delle proprietà, registra i plugin, ecc. L’inizializzazione deve essere eseguita una volta all’avvio dell’applicazione; per esempio, il metodo main() di Spoon chiama KettleEnvironment.init() per preparare l’ambiente per l’utilizzo da Spoon.
Il metodo init() accetta il parametro simpleJndi di tipo boolean che governa se configurare o no il Simple JNDI (che per default viene configurato). Daniele Licitra mi ha segnalato che la configurazione del Simple JNDI crea qualche problema in ambiente Wildfly, problema che ha poi risolto inizializzando Kettle senza la configurazione del SimpleJNDI. Per tutti i dettagli invito a leggere la questione su StackOverflow.
5. Conclusioni
L’ambiente di Data Integration (Kettle) offerto da Pentaho è davvero interessante, ricco di molte potenzialità. Di uno strumento informatico, una delle qualità che personalmente apprezzo è la possibilità di creare estensioni e punti d’integrazione nel minor tempo possibile, Kettle a mio avviso include questa qualità.
Per coloro il cui mestiere è l’integrazione di sistemi informatici, la prima caratteristica apprezzata è la facilità d’interazione con la cosiddetta “scatola nera”, ecco il motivo per cui ho volutamente introdotto in quest’articolo le API offerte da Kettle, in particolare ho esaltato le parti delle API che sono solitamente utilizzate in tutti gli scenari d’integrazione.
[1] Pentaho Data Integration offre una soluzione ETL utilizzando un approccio innovativo e orientato ai metadati. Con un’intuitiva interfaccia grafica di progettazione, un’architettura scalabile e basata su standard. Per maggiori info consultare il portale http://kettle.pentaho.com/
[2] E’ l’interfaccia grafica per la creazione e la modifica di Job e Trasformazioni. Può essere inoltre utilizzato per eseguire Job e Trasformazioni con la possibilità di fare operazione di debug.
[3] Extract, Transform, Load (ETL) è un’espressione in lingua inglese che si riferisce al processo di estrazione, trasformazione e caricamento dei dati in un sistema di sintesi (data warehouse, data mart, etc…). I dati sono estratti da sistemi sorgenti quali database transazionali (OLTP), comuni file di testo o da altri sistemi informatici (ad esempio, sistemi ERP o CRM).













